Text Embeddings by Weakly-Supervised Contrastive Pre-training
Introduction
- Contrastively train embeddings from curated web-scale text pair dataset
- Contrastive-learning recipe - in-batch negatives with large batch size
- Call this method - Weakly Supervised Contrastive Pre-Training
Data Collection - CCPairs
Harvesting Semi-Structured Data Sources
let (q,p) denote query, text pairs. The data sources used are:
- (post, comment) from Reddit
- (question, upvoted answer) from Stackexchange
- (entity name + section title, passage) from English Wikipedia
- (title, abstract) and citation pairs from Scientific papers
- (title, passage) pairs from Common Crawl
~ 1.3B text pairs (mostly from Reddit and Common Crawl)
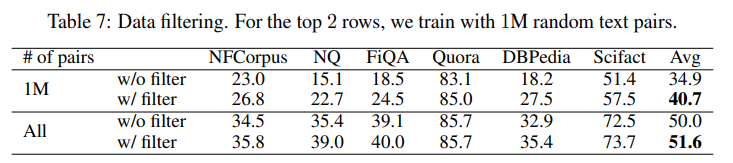
Consistency-Based Filtering
- A model is trained on the 1.3 B noisy text pairs.
- It is then used to rank each pair against 1 M random passages.
- A text pair is kept if it falls in top-k ranked list.
- k=2 based on manual inspection, ends up with ~270 M pairs.
Assumption - When trained on noisy datasets, neural networks tend to memorize the clean labels first and then gradually overfit the noisy labels.
Training
Contrastive Pre-Training
- Distinguish relevant text pairs from other irrelevant pairs
- Given a collection of text pairs \(\{(q_i, p_i)\}_{i=1}^n\), assign a list of negative passages \(\{p_{i,j}^-\}_{j=1}^m\) for the i-th example.
-
InfoNCE contrastive loss \(min L = -\frac{1}{n}\sum_ilog\frac{e^{s_\theta(q_i,\; p_i)}} {e^{s_\theta(q_i,\; p_i)} + \sum_je^{s_\theta(q_i,\; p_{ij}^-)}}\) , where \(s_\theta(q,p)\) is a scoring function between q and p parametrized by \(\theta\).
- Pre-trained transformer encoder + average pooling over output layer.
- Use shared encoder and break symmetry by adding prefix identifiers “query:” and “passage”.
- Negative Sampling - in-batch negatives.
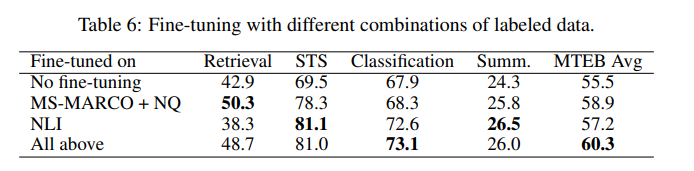
Fine-tuning with Labeled Data
- Supervised finetuning with NLI(Semantic Textual Similarity) and MS-MARCO + NQ (Retrieval).
- Mined hard negatives from Cross encoder for MS-MARCO and NQ datasets.
- NLI - use contradiction sentences as hard negatives.
- Loss function is combination of distillation and contrastive loss: \(min \ D_{KL}(p_{ce}, p_{stu}) + \alpha L_{cont}\) where \(p_{ce}\) and \(p_{stu}\) ae the probabilities from the cross-encoder teacher mdoe and student model.
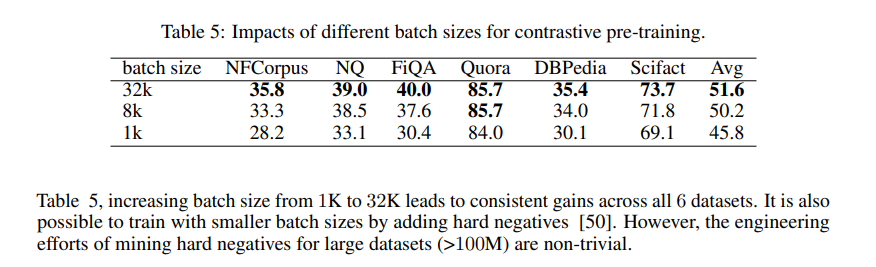
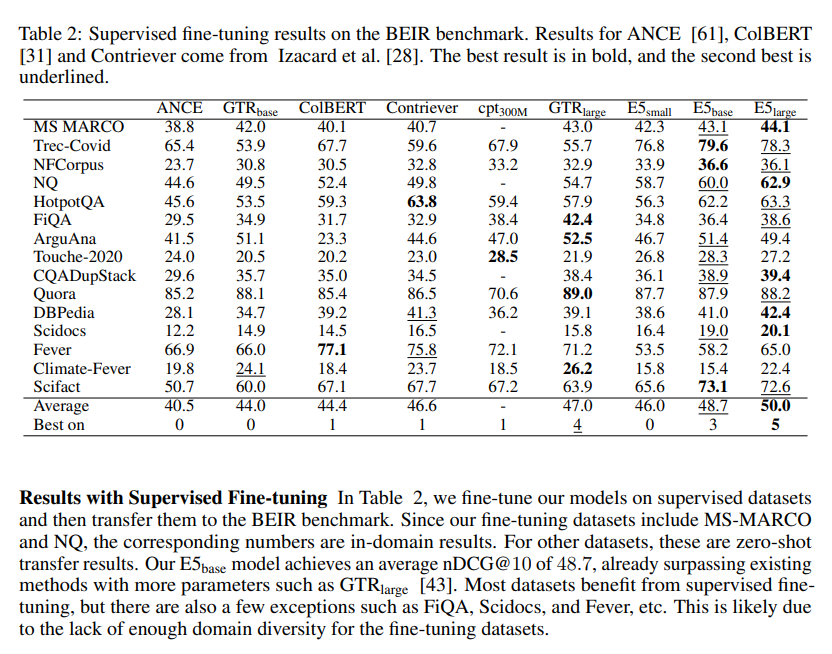
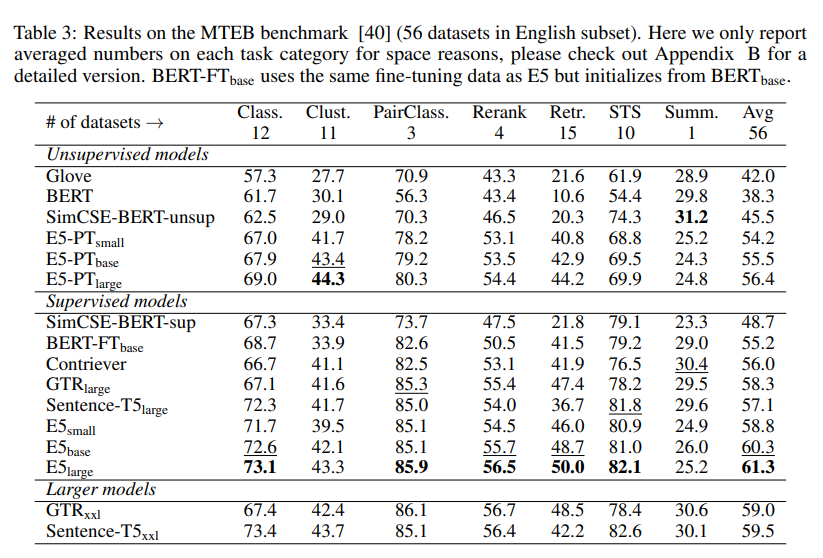
Experiments
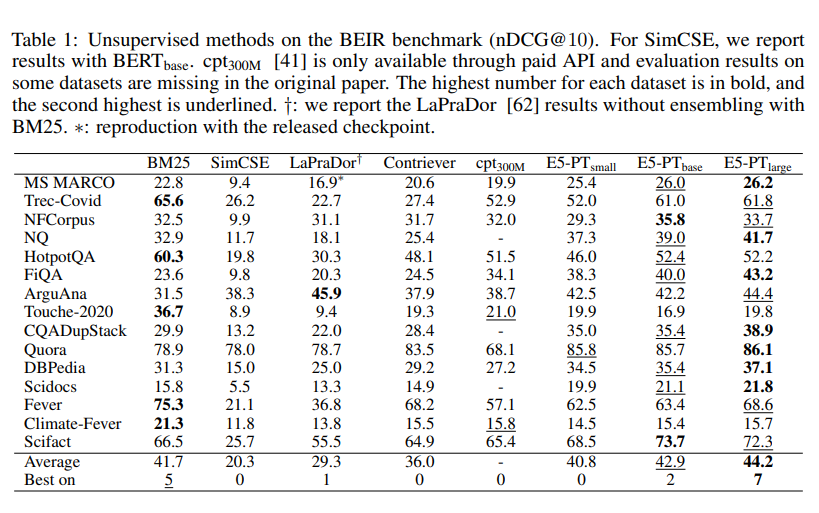
Ablation