BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
Introduction
- Addresses the following challenges related to versatility of text embeddings:
- Most embeddings tailored only for English.
- Existing embeddings trained for one single retrieval functionality.
- Most models only support short inputs.
-
Proposes a model which supports multi-linguality, multi-functionality and multi-granularity.
-
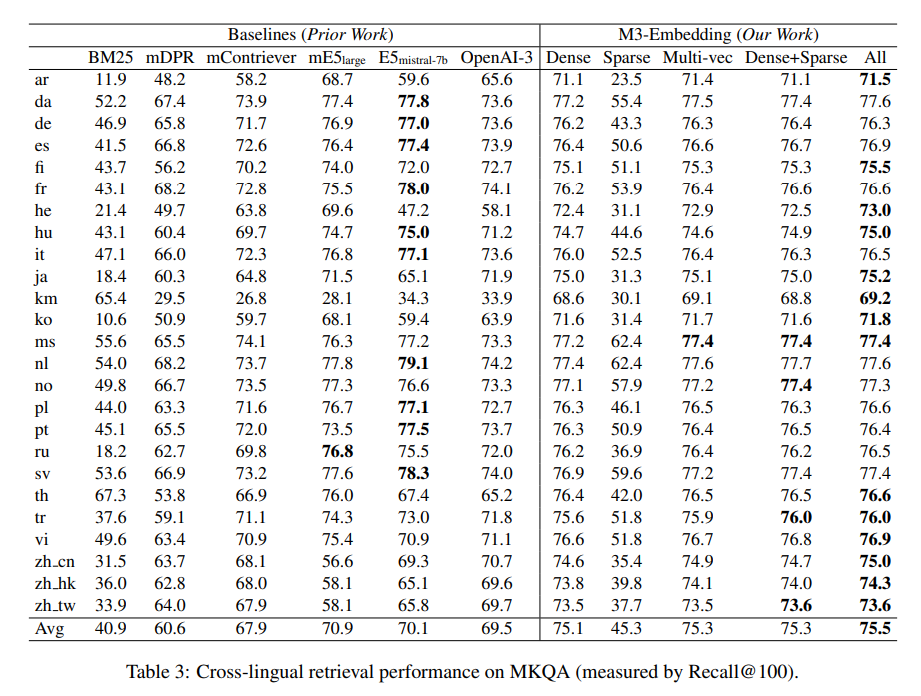
Formally, given a query q in an arbitrary langugae x, M3 embeddings are able to retrieve document d in language y from the corpus \(D^y: d^y \leftarrow fn^*(q^x, D^y)\)
- \(fn^*(.)\) can be - dense, sparse/lexical or multi-vector retrieval.
- y can be another language or same as x.
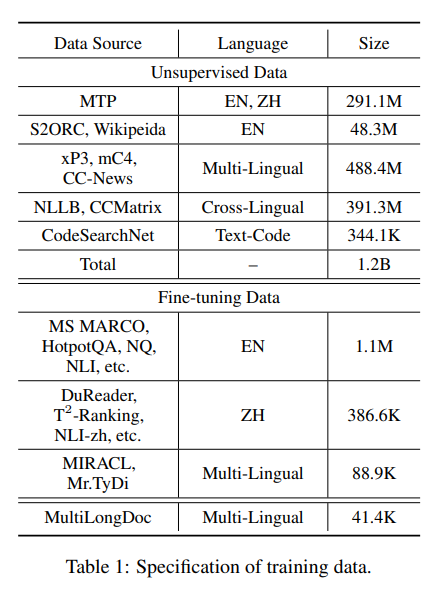
Data Curation
- Three data sources:
- Unsupervised data:
- extract title-body, title-abstract, instruction-output, etc.
- from multi-lingual corpora like Wikipedia, S2ORC, xP3, mC4, CC News. Also, parallel sentences from NLLB and CCMatrix.
- Labelled data:
- High quality fine tuning data.
- eg- Hotspot QA, Trivia QA, NQ, MS MARCO, Mr. Tydi, MIRACL.
- Synthetic Data:
- to mitigate shortage of long document retrieval tasks and introduce extra multi-lingual finetuning data.
- Sample lengthy articles from Wiki/MC4 and randomly choose paragraphs.
- Use GPT 3.5 to generate questions based on these paragraphs.
- Unsupervised data:
Hybrid Retrieval
Dense Retrieval
- Use the normalized hidden state of [CLS] token for representation of query, \(e_q\) and passage, \(e_p\).
- relevance score: \(s_{dense}= <e_p, e_q>\)
Lexical Retrieval
- Use output embeddings to estimate importance of each term
-
Term weight of each term t in a query q: \(w_{qt}=Relu(W^T_{lex}H_q[i])\) where \(W^T_{lex} \ \epsilon \ R^{d \times 1}\).
- same for passage
- relevance score computed by joint importance of co-existed terms: \(s_{lex} = \sum_{t\epsilon q \cap p}(w_{qt} \ * \ w_{pt})\)
Multi-Vector Retrieval
- Use entire output embeddings for query/passage representation.
- \[E_q = norm(W_{mul}^TH_q), E_p = norm(W_{mul}^TH_p), W_{mul} \ \epsilon \ R^{d \ \times \ d}\]
- Use late interaction like colbert to compute fine-grained relevance score: \(s_{mul} = \frac1N \sum_{i=1}^Nmax_{j=1}^ME_q[i].E_p^T[j]\) N and M are lengths of query and passage.
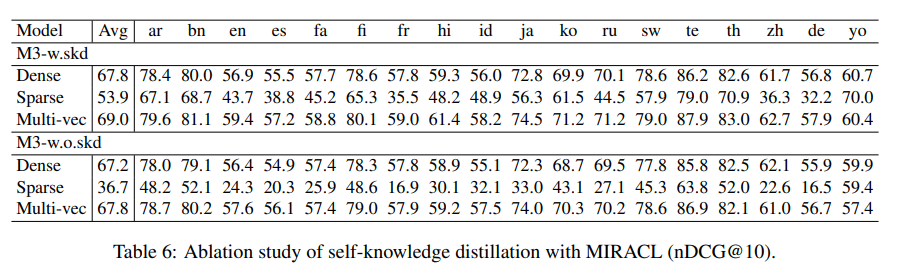
Self-Knowledge Distillation
- Minimize InfoNCE loss: \(L = -\log \frac{\exp(s(q,p^*)/\tau)}{\sum_{p\epsilon\{p^*, P^`\}}exp(s(q,p)/\tau)}\)
where \(p^*\) and \(P^`\) stand for positive and negative samples to query q; s(.) is any of the functions within {\(s_{dense}(.), s_{lex}(.), s_{mul}(.)\)}.
-
Naive multi-objective training unfavourable since training objectives can be mutually conflicting.
-
Use self knowledge distillation, predictions from different retrieval methods can be integrated.
-
simplest form, \(s_{inter} = s_{dense}(.)+ s_{lex}(.)+ s_{mul}(.)\). use this as the teacher.
-
loss function of each retrieval method: \(L_*^`=-p(s_{inter}) * \log p(s_*)\)
\(p(.)\) is softmax activation, \(s_*\) is any of the members within {\(s_{dense}(.), s_{lex}(.), s_{mul}(.)\)}.
- \[L' = \frac{L^`_{dense} + L^`_{lex} + L^`_{mul}}{3}\]
- \[L_{final} = L^` + L\]
- Fist text encoder is pretrained on unsupervised data where only dense retreival is trained.
- Self knowledge distillation is applied to second stage when model is finetuned on labeled and synthetic data.
- ANCE used for hard negative.
Efficient Batching
- Keep batch size as large as possible to ensure discriminativeness of embeddings.
- Training data pre-processed by being grouped by sequence length.
- Similar sequence length reduces sequence padding and improves gpu utilization.
- For long sequences, mini-batch is further divided into sub-batches.
- Iteratively encode each sub-batch using gradient checkpointing and gather all generated embedding.
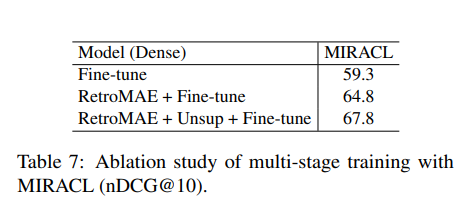
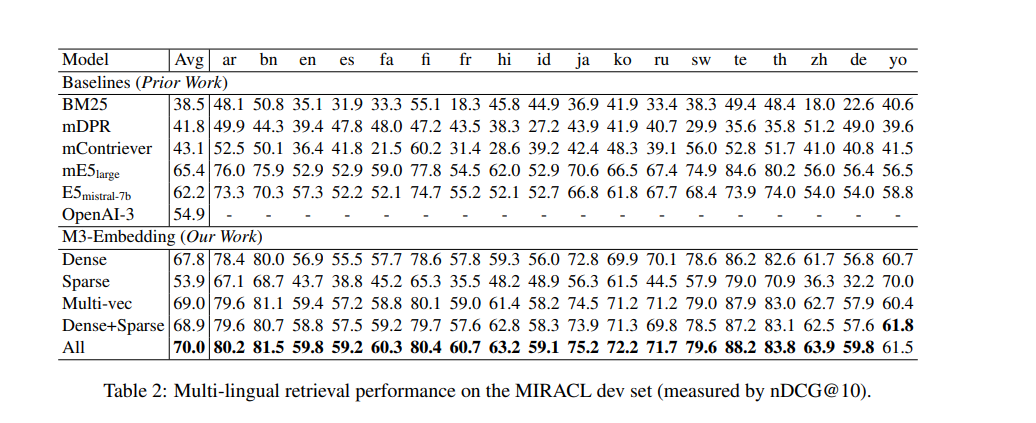
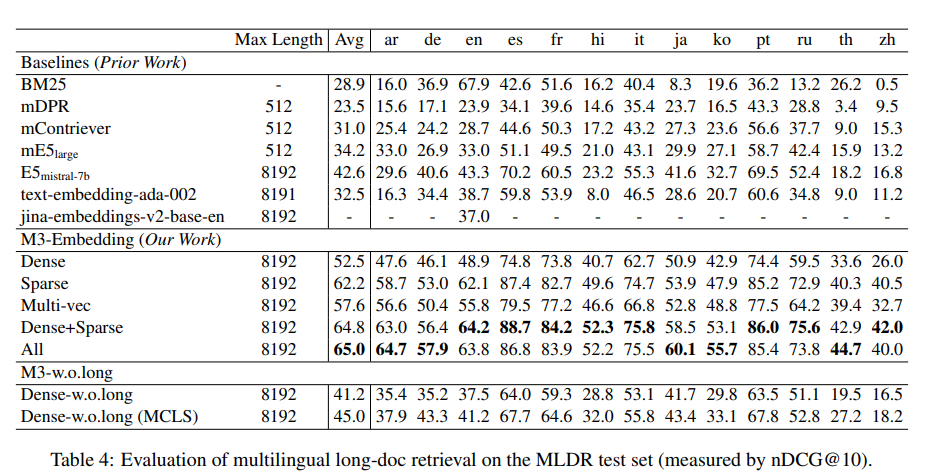
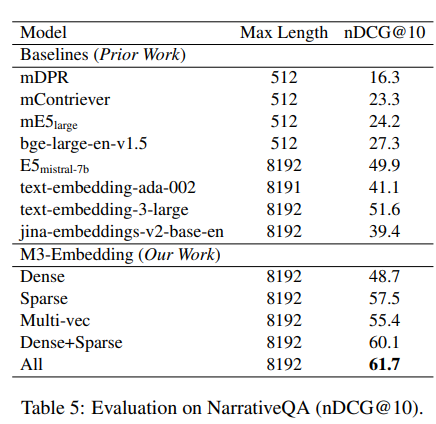
Experiments
Ablation