RoFormer: Enhanced Transformer with Rotary Position Embedding
Introduction
- Existing approaches to the relative position embedding based on adding position encoding to context representation.
- Current work, introduces Rotary Position Embedding (RoPE).
- leverages positional information into learning process of Pretained Language Models.
- RoPE decays with relative distance increased.
- desired for natural language encoding.
- Achieves better performance in long text benchmarks compared to alternatives.
Related Work
Preliminary
-
let \(S_N=\{w_i\}_{i=1}^N\) be a sequence of \(N\) input tokesns with \(w_i\) being the \(i^{th}\) element.
-
The corresponding word embedding is denoted as: \(E_N=\{x_i\}_{i=1}^N\) where \(x_i \in R^d\) is the d-dimensional word embedding of token \(w_i\) without position information.
-
The self-attention first incorporates position information to the word embeddings and transforms them into queries, keys and value representations.
where \(q_m,k_n,v_n\) incorporate the \(m^{th}\) and \(n^{th}\) positions through \(f_q, f_k \ and \ f_v\) respectively.
- query and key are then used to compute attention weights and output is computed as weighted sum over the value:
- Existing approaches for transformer based position encoding focus on choosing a suitable function to form equation (1).
Absolute Position Embedding
- Typical choice of eq. (1)
\(f_{t:t \in \{q,k,v\}}(x_i, i) = W_{t:t\in \{q,k,v\}}(x_i + p_i)\) where \(p_i\) is a d-dimensional vector depending on position of token \(x_i\).
- Two types:
-
Use a set of trainable vectors. \(p_i\in\{p_t\}_{t=1}^L\) where \(L\) is maximum sequecne length.
-
Use sinusoidal function: \(p_{i, 2t} = \sin(i/10000^{2t/d})\) \(p_{i, 2t+1} = \cos(i/10000^{2t /d})\)
- Each dimension of the positional encoding corresponds to a sinusoid
- The wavelengths form a geometric progression from \(2\pi\)to \(10000 \times2\pi\)
- For any fixed offset k, \(p_{i+k}\)can be represented as a linear function of \(p_i\).
- Current proposal related to this intuition.
-
Relative Position Encoding
-
Shw et.al. [2018]
\(f_q(x_m) = W_qx_m\) \(f_k(x_n,n)=W_k(x_n+\tilde{p_r^k})\) \(f_v(x_n,n)=W_v(x_n+\tilde{p_r^v})\)
where \(\tilde{p_r^k},\tilde{p_r^v} \in \R^d\) are trainable position embeddings.
- \(r=clip(m-n, r_{min}, r_{max})\) represents relative distance.
-
Dai et al. [2019]
\[q_m^Tk_n = x^T_mW^T_qW_kx_n + x^T_mW^T_qW_kp_n + p^T_mW^T_qW_kx_n + p^T_mW^T_qW_kp_n\]- Replace absolute position embedding \(p_n\) with its sinusoidal-encoded relative counterpart \(\tilde{p}_{m-n}\)
- Replace absolute position \(p_m\)in third and fourth term with two trainable vectors independent of the query positions.
- \(W_k\) distinguished for content-based and locatin based vectors.
-
Position information in the value term is removed.
\[q_m^Tk_n = x^T_mW^T_qW_kx_n + x^T_mW^T_q\tilde{W_k}\tilde{p}_{m-n} + u^TW^T_qW_kx_n + v^TW^T_q\tilde{W_k}\tilde{p}_{m-n}\]
-
He et al. [2020]
\[q_m^Tk_n = x^T_mW^T_qW_kx_n + x^T_mW^T_qW_k\tilde{p}_{m-n} + \tilde{p}_{m-n}^TW^T_qW_kx_n\] -
These methods directly add position information to context repesentation.
Proposed Approach
Formulation
- We require inner product of query \(q_m\) and key \(k_n\) to be formulated by a function \(g\), which takes as input only word embeddings \(x_m,x_n\) and their relative position \(m-n\).
Rotary Position Embedding
2D Case
- Solution : Use geometric properties of vectors in 2-d and their complex forms(Express other terms also as complex numbers for the equations to make sense).
\(f_q(x_m,m)=(W_qx_m)e^{im\theta}\) \(f_k(x_n,n)=(W_kx_n)e^{in\theta}\) \(g(x_m,x_n,m-n)=Re[(W_qx_m)(W_kx_n)^*e^{i(m-n)\theta}]\)
where \(Re[.]\) is the real part of complex number and \((W_kx_n)^*\) is conjugate complex of \((W_kx_n)\), \(\theta\in R\) is a preset non-zero constant.
- In multiplication form:
General form
- To generalize the results to any \(x_i\in R^d\) where \(d\) is even, we divide the d-dimension space into \(d/2\) subspaces and combine them:
is the rotary matrix with pre-defined params \(\Theta=\{\theta_i=10000^{-2(i-1)/d}, i \in [1,2,...,d/2]\}\)
- Applying to self-attention equation:
Properties of Rope
- Long Term Decay
- Computational efficient expression (because of sparsity):
Evaluation
Machine Translation

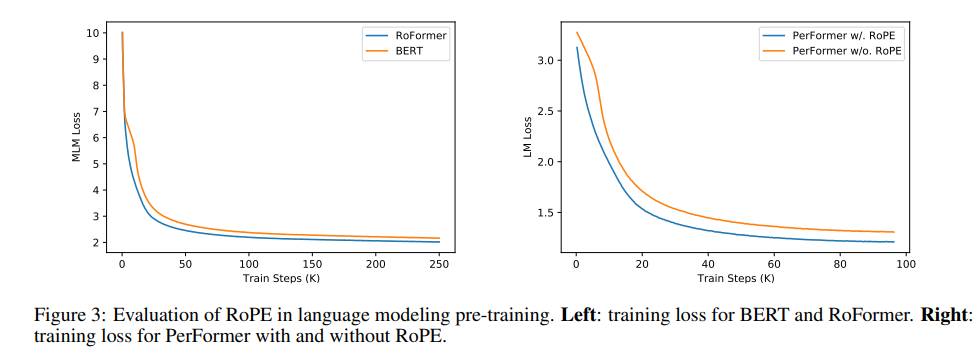
Pre-training Language Modeling
Fine-tuning on GLUE tasks

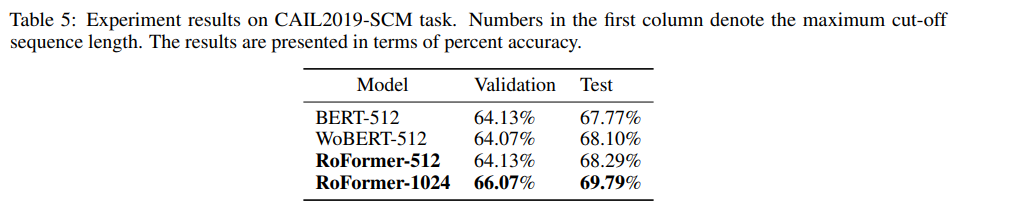
Evaluation on Chinese Data